Was ist OCR?
OCR (Optical Character Recognition, optische Zeichenerkennung) ist eine Technologie, die Text in gescannten PDFs oder Bildern erkennt und ihn in echten, bearbeitbaren Text umwandelt. Anstatt mit flachen Bilddateien zu arbeiten, können Sie den Inhalt durchsuchen, kopieren und bearbeiten – genau wie bei einem normalen PDF.
PDFgear bietet zwei Hauptoptionen für OCR, je nach Ihrem Bedarf:
Gescanntes PDF durchsuchbar machen
Mit dieser Option führt PDFgear OCR direkt auf Ihrem gescannten PDF aus. Das Erscheinungsbild der Datei bleibt gleich, aber der Text wird auswählbar und bearbeitbar. Sie können:
- Nach Wörtern oder Phrasen suchen
- Text markieren und kopieren
- Den Inhalt direkt im PDF-Editor bearbeiten
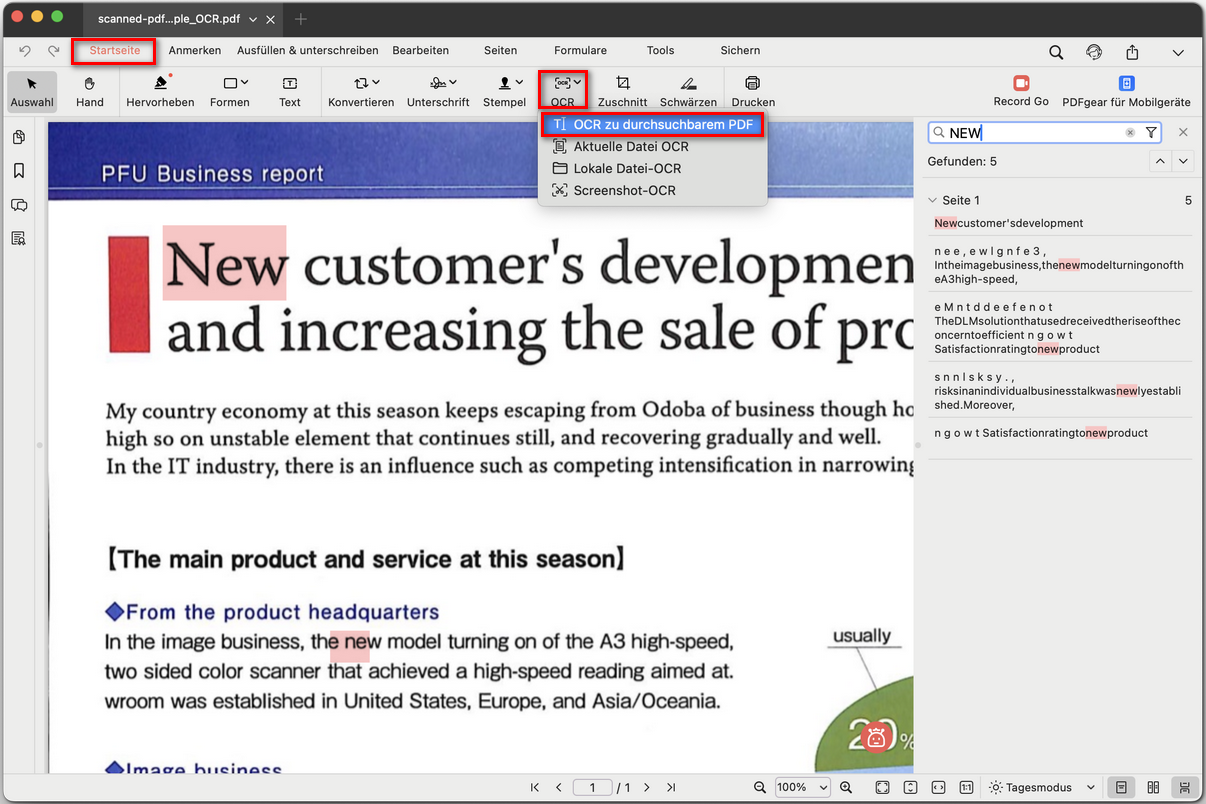
Gescanntes PDF durchsuchbar machen
Dies ist die beste Wahl, wenn Sie direkt in der PDF-Datei weiterarbeiten möchten.
Text aus einem gescannten PDF extrahieren
Manchmal müssen Sie das PDF nicht bearbeiten, sondern möchten nur den Text daraus übernehmen. PDFgear unterstützt auch die OCR-Texterkennung, um erkannten Text als reinen Inhalt zu extrahieren. Dies kann für das gesamte Dokument oder nur für ausgewählte Bereiche erfolgen.
- Den Text schnell kopieren
- In einer anderen Datei speichern oder exportieren
- Den Inhalt wiederverwenden, ohne ihn neu zu tippen
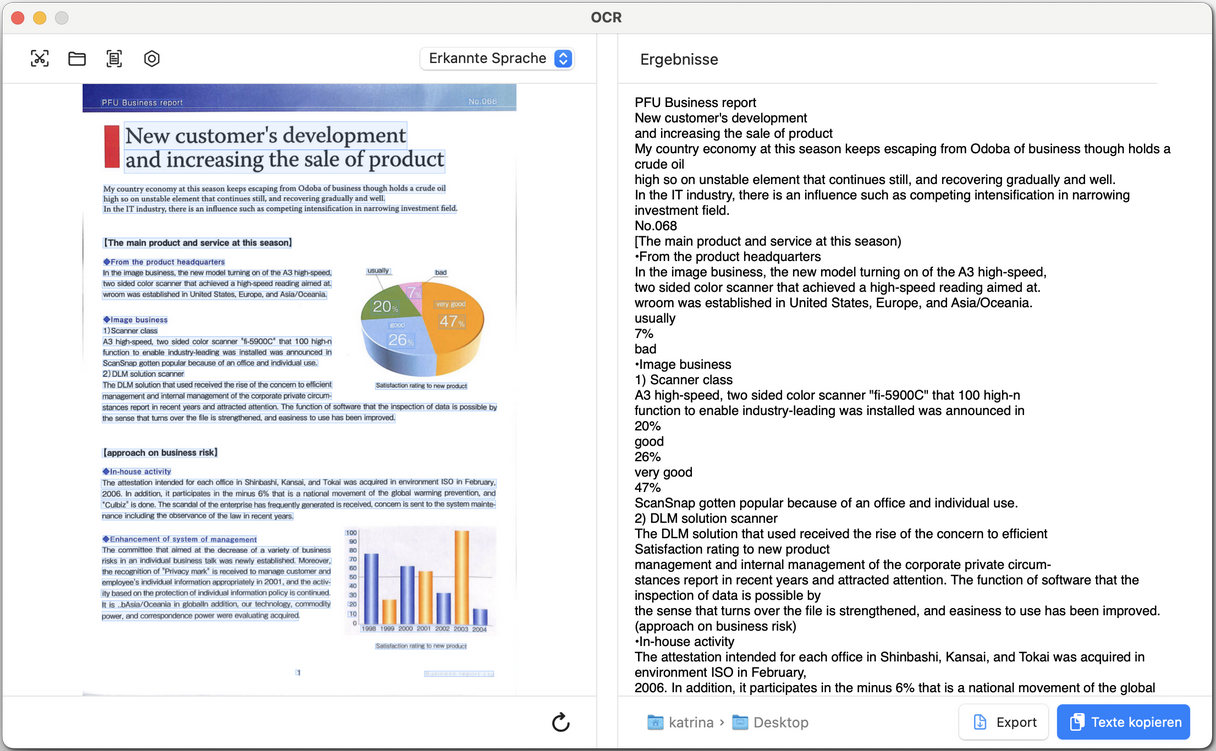
Text aus gescanntem Bild extrahieren
Dies ist die ideale Option, wenn Sie Text aus einem gescannten Dokument einfach wiederverwenden möchten.